Automating Cluster Benchmarking: Measure, Compare & Archive Compute Resources’ Performance

Stefan Gary
Team Lead, Solutions Engineering
Challenges with Streamlining Multiple Cluster Job Schedulers
High performance computing (HPC) is evolving rapidly as it shifts from a single-site paradigm to an increasingly growing array of different hardware, systems, and localities. Parallel Works ACTIVATE simplifies this complexity by automating cloud resource provisioning and centralizing access to compute environments.
With this streamlined access to different cluster job schedulers (e.g. Slurm and Kubernetes) new challenges emerge:
- Understanding and comparing cluster performance
- Automating benchmarking to generate data for AI-driven job placement
Parallel Works is addressing these challenges via a three-part strategy:
Three-Step Framework to Benchmark HPC Resources using ACTIVATE, Parsl-Perf (and other applications), and MLFlow
The first consideration is the benchmark itself. There is tremendous variety in the compute needs of HPC applications, and no single benchmark fully describes the capabilities of any resource. ACTIVATE’s workflows provide portable, reproducible recipes for automating the deployment of a range of benchmarking software.
In benchmarking across diverse resources, Parsl-Perf (an open-source performance benchmark for Parsl) stands out because it is:
- Open source and easy to install
- Portable across architectures due to Parsl’s many built-in providers
- Designed to test cluster schedulers by quantifying the number of tasks per second submitted
The speed of job submission is a critical metric for high-throughput computing and reflects one important dimension of cluster performance and stability.
Secondly, it is essential to run benchmarking within an archiving and metadata collection framework so that the results have meaning beyond the immediate context of when and where they were run. One open-source solution to tracking benchmark runs is MLFlow. While typically used to track specifically the training of machine learning models, MLFlow can associate strings (i.e. “tags”) and numerical inputs (i.e. “parameters”) and outputs (i.e. “metrics”) with a series of individual runs.
Workflows on Parallel Works ACTIVATE run Parsl-Perf within a wrapper that automatically gathers compute resource information, tracks benchmark results, and pushes everything into an MLFlow database that can be queried and visualized. The next step is to generalize the wrapper so that it can launch, tag, and archive other benchmark applications in addition to Parsl-Perf.
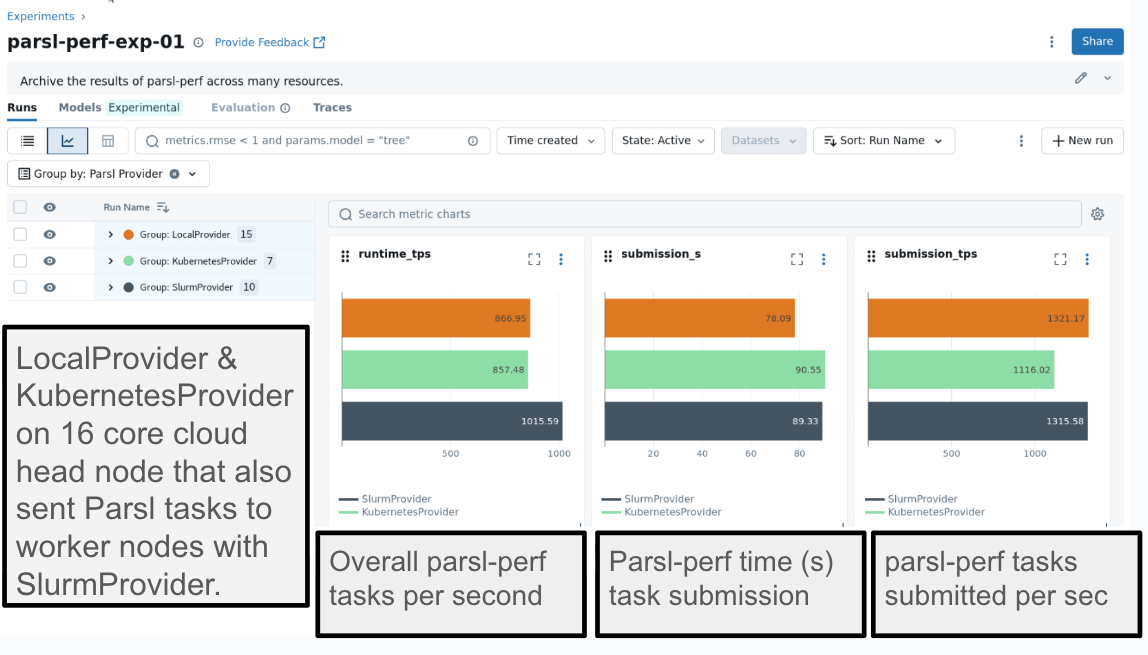
Screenshot of MLFlow interface, with descriptive labels in bold outlined boxes, displaying results within a database of Parsl-Perf runs whose metadata was automatically collected alongside the running of the benchmark. In this case, the 16-core head node of the cluster first ran Parsl-Perf tests with a LocalProvider (i.e. direct access to CPUs), a Kubernetes cluster provisioned locally on the head node (i.e. to test Kubernetes overhead), and to Slurm worker nodes.
Finally, the third aspect of Parallel Works’ benchmarking strategy is scaling up through engagement with HPC practitioners. The code to reproduce this workflow for archiving Parsl-Perf runs is publicly available (start here), and we plan to test this approach across a larger set of HPC systems.
Since MLFlow databases are structured as a series of many small files, it's possible to share moderate-sized MLFlow databases on GitHub, visualize them on nearly any resource (laptop or cluster), and contribute to them via pull requests without merge conflicts.
We would be delighted to see what kinds of Parsl-Perf runs you create!
Learn more about Compute Resource Management with Parallel Works
As more benchmark runs are archived, we can get a clearer picture of scheduler performance across a broad range of resources.
Watch Stefan Gary's presentation from ParslFest 2025 that describes this study in depth.
Learn more about ACTIVATE here.
Sign up for a demo to see ACTIVATE in action.