
v4 is a foundational release of the Parallel Works platform, with a completely reimagined workflow framework, cluster filesystem flexibility, and several other improvements.
What's new?
Reimagined Workflow Framework
Over the past several months, the Parallel Works engineering team has been working through redesigning our workflow engine and migrating from our current workflow solution to a completely custom-built solution based on user feedback. Before today, we utilized the Galaxy Project as our backend solution for workflow orchestration. The integration of Galaxy has served us very well since its adoption in 2015. However, the need for a more custom solution became obvious over time, based on the expanding needs of our users and the scope of our product.
Last year, we put most of our efforts into making a seamless user experience to create on-demand cloud clusters and all of the infrastructure required to get Slurm running in the cloud. Cloud clusters quickly became foundational to our product, and now we're excited to build on top of that work with these latest updates. The scope of this update is detailed in the following sections.
Unified Workflow Submission Page
Workflows and cluster configuration now share the same form design. We hope this makes it easier to get ramped up on the platform and start running workflows quickly.
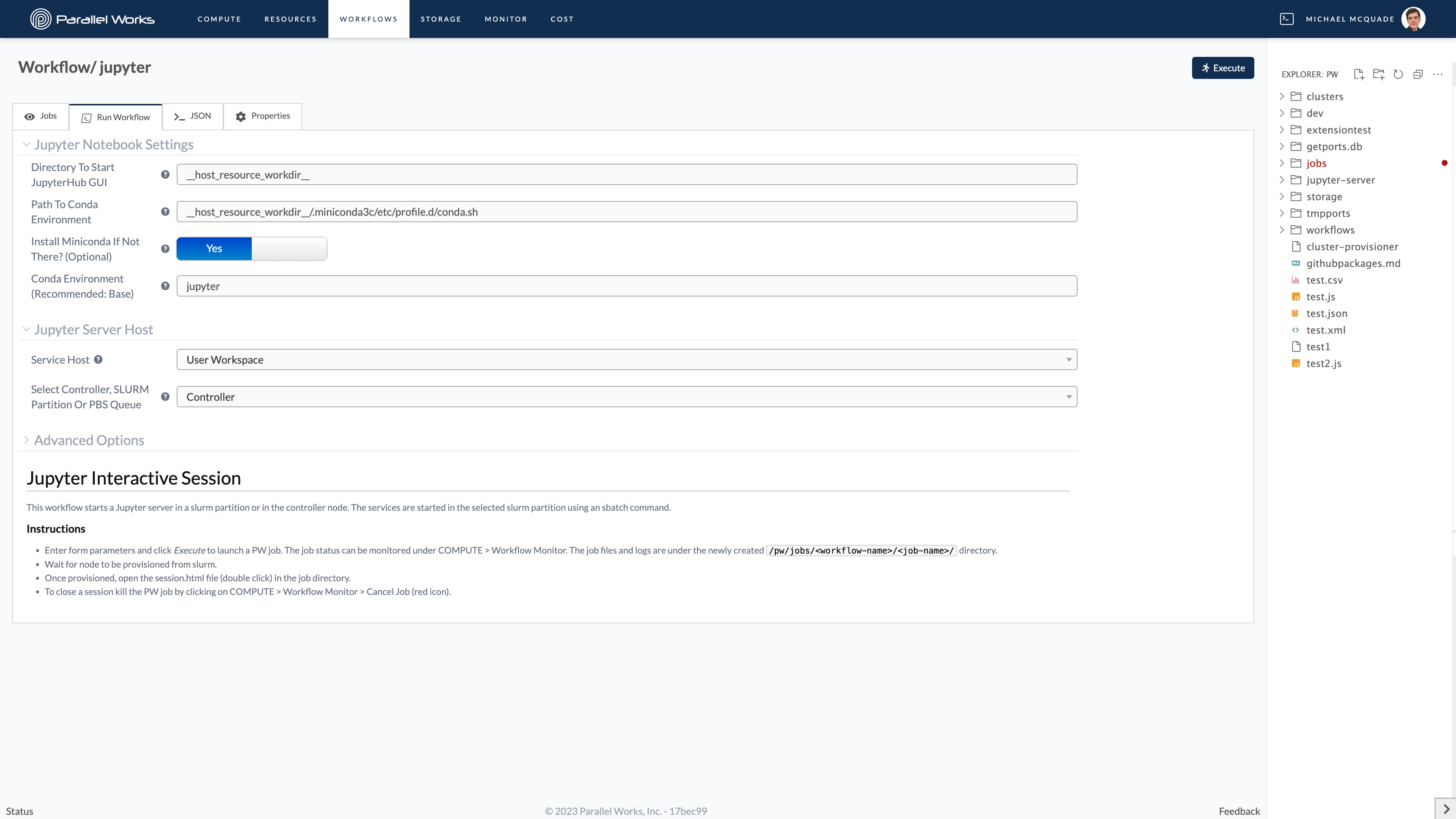 Unified Workflow Submission Page
Unified Workflow Submission Page
workflow.xml
At this time, we will continue to utilize the workflow.xml format that was created by the Galaxy Project, but we will be adding additional functionality to the format over time and will be providing a new alternative format in .yml in a future minor release.
The workflow.xml file now supports a new computeResource tag that allows the workflow developer to get information about a cluster that will be used to run the workflow. The user who runs the workflow will be able to select a cluster from a dropdown menu on the workflow submission page. The named computeResource tag will be populated with the information about the cluster that the user selects at runtime.
Here is an example of how to include a computeResource tag:
<param name='resource' type='computeResource' label='Service host' hideUserWorkspace='false' help='Resource to host the service'></param>
 A custom
A custom computeResource tag on the platform
New Workflow Inputs Format
Previously, we automatically set environment variables based on the parameters specified in the workflow.xml file and the workflow user's choices on the workflow submission page. Now, we have moved away from environment variables and instead use a new inputs.json file to pass parameters to the workflow.
It is up to the workflow developer to parse the inputs.json file and use the parameters in the workflow. The names of the parameters in the inputs.json file will match the names of the parameters in the workflow.xml file.
To make it easier to transition, we also create a inputs.sh file next to the inputs.json file at the root of the job directory which contains the same information as the inputs.json file, so that the workflow developer can source the inputs.sh file in their workflow to continue using the parameters as environment variables.
Unified Logging
Workflows that write to stdout or stderr will now have their output captured into a single log file called logs.out. Workflow developers can still opt to write to additional log files. Additionally, we plan to support workflow developers specifying the location of these logs in a future minor release.
Workflow Job View
We've introduced a new page for workflow jobs, enabling users to directly view the status and logs of current or past jobs from the user interface. This is now the default page that users will see when they click on a workflow from the workflow list page. The logs that show up on this page are the same logs that are captured in the logs.out file in the job directory. The logs are updated in real time as the workflow runs.
Flexible Filesystems
We have introduced a new type of storage we call "persistent storage." These storage resources are provisioned independently of the cluster and can be mounted on the cluster while it is running. This allows users to mount additional storage on the cluster without having to stop and start the cluster.
For the new AWS and GCP persistent bucket options, these are mounted via the open-source tool goofys, which uses FUSE and allows mounting and using bucket storage as if it were a traditional filesystem.
For more information, please see our blog post and Storage in our user guide.
Cross-Group Storage Sharing
Users can now share storage with any group they're in. When a user shares a storage with a group they're in, any user in that group will be able to mount the storage to their cloud clusters. This is useful for sharing data between multiple clusters and multiple groups. The group assigned to the storage is the group that will be responsible for paying for the storage.
For more information on our new storage features, including how to share storage and how to mount shared storage, see our documentation on Managing Storage, Configuring Storage, and Attaching Storage.
Redesigned Dashboards
We've revamped our dashboards to enhance performance and usability. The new dashboards are integrated with our React.js powered application, and should feel much more responsive and snappy.
You can find the dashboards at the top of the page by choosing Cost or Monitor. For more info, check out our documentation on Monitoring Costs. Documentation for the new Monitor dashboard is coming soon.
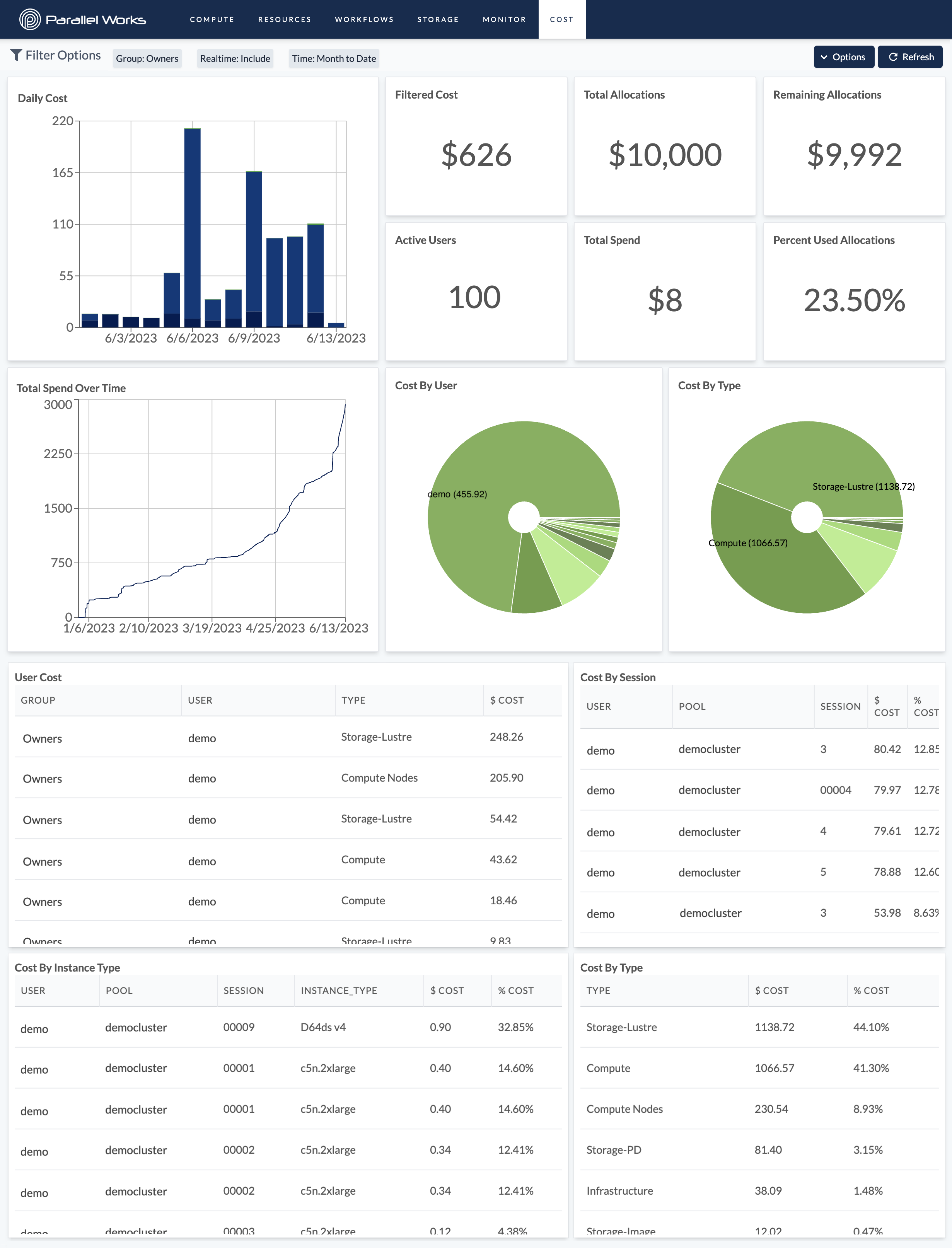 The new Cost dashboard
The new Cost dashboard
New Notifications System
We have added a new notifications system that's accessible from the top right of the navigation bar. This system will allow us to send notifications to users.
Workflow developers can also utilize this system within their workflows to alert users. An example of this is sending a notification to a user when a workflow completes or becomes interactive. If the notification contains a link, users can click on the notification to open it.
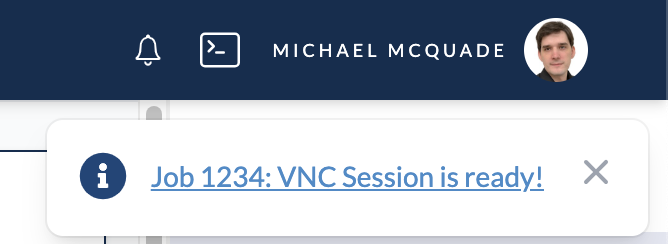 New ready/interactive notification on the platform
New ready/interactive notification on the platform
To access previous notifications, click on the bell icon in the top right of the navigation bar. You may archive notifications by clicking on the archive icon next to the notification.
 Dropdown menu for previous notifications
Dropdown menu for previous notifications
Cluster Runtime Alerts
Occasionally, clusters might accidentally be left on longer than necessary, leading to unnecessary costs even when no real work is being carried out. We now provide users an option to configure an alert that will send an email when the cluster has been running for a configured amount of time. These emails will be sent at the configured interval until the cluster is stopped or the alert is disabled.
For more information, see our documentation for Creating Clusters and Configuring Clusters.
Allocation Thresholds
Now organizations can create and customize thresholds to take configurable actions when budget allocations are exceeded. For example, an organization can now configure a threshold that will automatically stop all clusters when a group reaches its allocation limit.
The actions that can be taken are:
- Notify (either the whole group or specific users)
- Freeze (prevent users in the group from starting new clusters against the allocation)
- Shutdown (stop all clusters in the group)
The decisions for these actions can be made by either our real-time cost estimation system, or by the CSP true cost data, which is our term for billing data retrieved directly from the CSP. True cost data is updated as soon as it's available, usually with a delay of a few hours up to a day. Real-time cost estimates are updated every 3 minutes.
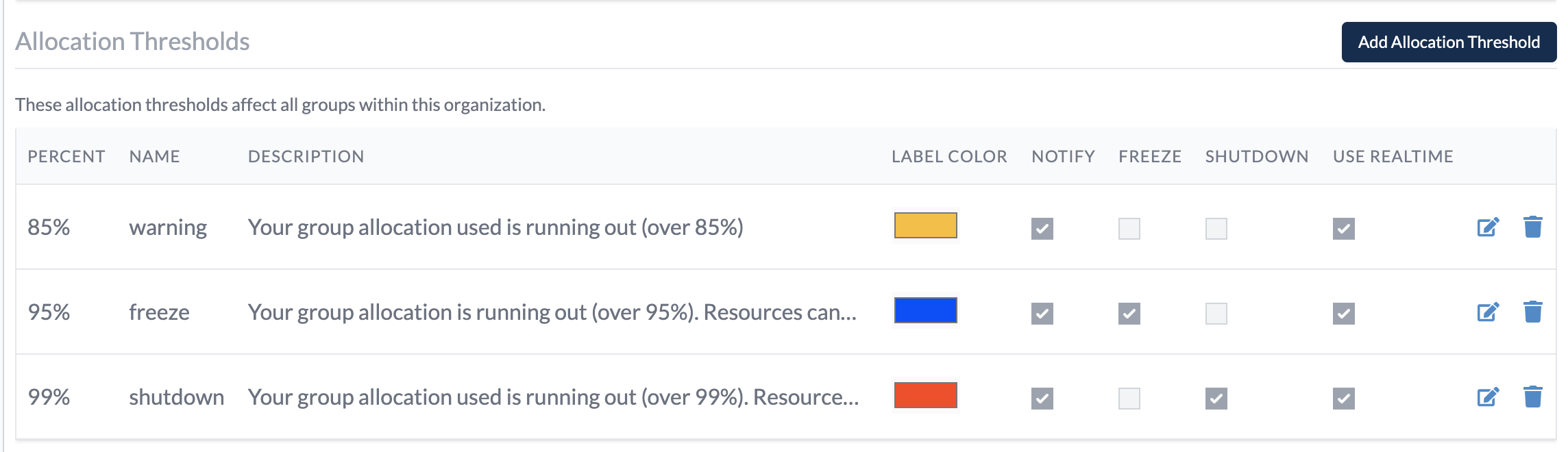 New allocation thresholds UI
New allocation thresholds UI
For more information, see our documentation on Allocation Thresholds.